Configuring data servers is a crucial aspect of ensuring smooth operations and maximizing performance in today’s data-driven world. In this comprehensive blog article, we will delve into advanced data server configurations that can take your organization’s data management to the next level. From optimizing performance to enhancing security measures, we will explore various techniques and best practices that will revolutionize the way you handle your data.
Whether you are a system administrator, database engineer, or simply interested in understanding the intricacies of data server configurations, this article will provide you with valuable insights and actionable steps to implement in your own environment. Join us as we journey through the vast realm of advanced data server configurations and unlock the true potential of your data infrastructure.
Load Balancing and Scalability
Load balancing plays a vital role in distributing workloads efficiently across multiple servers, optimizing performance, and ensuring scalability. By distributing incoming requests evenly, load balancers prevent any single server from becoming overwhelmed, thereby improving response times and avoiding overutilization.
When it comes to load balancing, there are various algorithms to consider. Round-robin is a simple algorithm that evenly distributes requests among servers, while weighted round-robin assigns different weights to servers based on their capabilities. Least connection algorithm directs incoming requests to servers with the fewest active connections, ensuring a balanced workload distribution.
Session Persistence
Session persistence, also known as sticky sessions, is essential when dealing with stateful applications. By maintaining session affinity, load balancers can ensure that subsequent requests from a particular client are always directed to the same server where the session was initiated. This allows for consistent data access and eliminates the need to replicate session data across servers.
Horizontal and Vertical Scaling
Scalability is a critical aspect of data server configurations. Horizontal scaling involves adding more servers to your infrastructure, allowing for increased capacity and workload distribution. Vertical scaling, on the other hand, involves upgrading existing servers by adding more resources, such as CPU, RAM, or storage. A combination of both scaling approaches can provide a highly scalable and flexible data server environment.
High Availability and Failover
High availability ensures that your data servers remain accessible even in the event of failures or outages. By implementing failover mechanisms, you can minimize downtime and maintain uninterrupted operations. Active-passive and active-active setups are two common strategies for achieving high availability.
Active-Passive Setup
In an active-passive setup, one server actively handles incoming requests while the other server remains in a standby state. The passive server continuously replicates data from the active server, ensuring synchronization. In the event of a failure, the passive server takes over seamlessly, minimizing disruptions and providing near-instant failover.
Active-Active Setup
An active-active setup involves multiple servers actively handling requests simultaneously. This setup allows for load balancing and better utilization of resources. In the event of a failure, the remaining servers can seamlessly take over the workload, ensuring uninterrupted service.
Heartbeat Monitoring
To detect failures and trigger failover, heartbeat monitoring is crucial. Heartbeat messages are exchanged between servers at regular intervals to confirm their availability. If a server fails to respond within a specified timeframe, the monitoring system initiates failover procedures, directing traffic to the standby server.
Data Replication and Disaster Recovery
Data replication is a key component of disaster recovery strategies, ensuring that data remains available and accessible even in the face of unexpected events. By replicating data to multiple locations, organizations can minimize the risk of data loss and maintain business continuity.
Synchronous Replication
Synchronous replication ensures that data is replicated in real-time to secondary servers. Every write operation is synchronized across multiple servers before being acknowledged, providing strict consistency and guaranteed data integrity. While synchronous replication offers robust protection, it may introduce additional latency due to the need for acknowledgment from multiple servers.
Asynchronous Replication
Asynchronous replication, on the other hand, allows for more flexibility by not requiring immediate synchronization. Write operations are acknowledged once they are committed to the primary server, and data is replicated to secondary servers in the background. Although asynchronous replication may introduce a slight delay, it offers higher performance and can tolerate network latency or intermittent connectivity issues.
Disaster Recovery Planning
Disaster recovery planning involves creating a comprehensive strategy to protect critical data and ensure its availability in the event of a disaster. This includes identifying potential risks, establishing recovery objectives, defining recovery procedures, and regularly testing the plan to ensure its effectiveness. A well-designed disaster recovery plan can help mitigate the impact of disasters, minimize downtime, and safeguard valuable data.
Optimizing Query Performance
Query performance plays a crucial role in ensuring efficient data retrieval and processing. By optimizing query performance, organizations can reduce response times, improve user experience, and enhance overall system efficiency. Several techniques can be employed to achieve optimal query performance.
Query Caching
Query caching involves storing the results of frequently executed queries in memory, allowing for faster retrieval when the same query is issued again. By avoiding the need to re-execute the same query and fetch data from disk, query caching significantly reduces response times and improves overall system performance.
Indexing Strategies
Indexes play a crucial role in speeding up data retrieval by providing efficient access paths to specific data subsets. By identifying the appropriate columns to index and utilizing different indexing techniques such as B-trees or hash indexes, organizations can dramatically improve query performance. It is important to carefully analyze query patterns and data access patterns to determine the most effective indexing strategy.
Query Optimization Tools
Query optimization tools help analyze query execution plans and suggest improvements to enhance performance. These tools provide insights into query performance bottlenecks, recommend index changes, and suggest query rewrites to optimize execution. By leveraging query optimization tools, organizations can fine-tune their queries and achieve significant performance gains.
Security Hardening and Access Control
Ensuring the security of data servers is of utmost importance in today’s threat landscape. Robust security measures and access control mechanisms must be implemented to safeguard sensitive data from unauthorized access and potential breaches.
Encryption
Encryption is essential for protecting data confidentiality. By encrypting data at rest and in transit, organizations can prevent unauthorized access even if the data falls into the wrong hands. Advanced encryption algorithms, such as AES (Advanced Encryption Standard), along with secure key management practices, ensure the integrity and confidentiality of sensitive data.
Secure Authentication
Implementing secure authentication mechanisms is crucial to prevent unauthorized access to data servers. Strong password policies, multi-factor authentication, and integration with identity management systems can help ensure that only authorized users can access the system. Additionally, implementing secure protocols like SSL/TLS for data transmission further enhances the security of data in transit.
Network Security Protocols
Network security protocols, such as firewalls, intrusion detection systems, and virtual private networks (VPNs), play a vital role in protecting data servers from external threats. Firewalls help filter incoming and outgoing network traffic, while intrusion detection systems monitor for suspicious activities. VPNs provide secure remote access to data servers, encrypting the communication between clients and servers.
Virtualization and Containerization
Virtualization and containerization technologies have revolutionized the way data servers are deployed and managed. These technologies offer increased resource utilization, simplified management, and enhanced flexibility in data server configurations.
Virtual Machines
Ngadsen test2
Virtual machines (VMs) allow multiple operating systems to run on a single physical server, enabling efficient resource utilization and isolation. By abstracting the underlying hardware, VMs provide a flexible and scalable environment for deploying data servers. Additionally, features like live migration enable seamless movement of VMs between physical servers without downtime.
Containers
Containers provide lightweight and isolated environments for running applications and services. Unlike VMs, containers share the host operating system, resulting in reduced resource overhead and faster startup times. Container orchestration platforms, such as Kubernetes, simplify the management of containerized data servers, enabling automatic scaling and high availability.
Monitoring and Performance Tuning
Continuous monitoring and performance tuning are essential to ensure the optimal functioning of data servers. By monitoring key performance metrics and proactively identifying bottlenecks, organizations can fine-tune their configurations and maintain peak performance.
Performance Metrics
Monitoring performance metrics, such as CPU utilization, memory usage, disk I/O, and network latency, provides insights into the health and performance of data servers. By establishing baseline metrics and setting thresholds, organizations can detect anomalies and take corrective actions before performance degradation impacts operations.
Monitoring Solutions
Various monitoring solutions, both open-source and commercial, are available to monitor data servers. These solutions provide real-time visibility into system performance, generate alerts on critical events, and offerdetailed reports for analysis. Popular monitoring tools include Nagios, Zabbix, Prometheus, and Datadog, each offering a range of features to monitor and optimize data server performance.
Identifying and Resolving Bottlenecks
When monitoring data servers, it is crucial to identify performance bottlenecks and take appropriate actions to address them. Bottlenecks can occur in various areas, such as CPU, memory, disk I/O, or network. By analyzing performance metrics and utilizing performance profiling tools, organizations can pinpoint the root causes of bottlenecks and implement optimizations, such as upgrading hardware, optimizing queries, or redistributing workloads.
Real-time Monitoring and Alerting
Real-time monitoring and alerting enable organizations to proactively identify and address performance issues before they impact operations. By setting up alerts based on predefined thresholds or anomaly detection algorithms, administrators can receive notifications for critical events, ensuring timely intervention and minimizing downtime.
Data Partitioning and Sharding
Data partitioning is a technique used to divide large datasets into smaller, more manageable subsets. By partitioning data, organizations can improve query performance, optimize storage utilization, and distribute workloads across multiple servers. Sharding takes data partitioning a step further by distributing data across multiple servers in a controlled manner.
Horizontal Partitioning
Horizontal partitioning involves dividing a dataset based on rows, where each partition holds a subset of rows. This technique is particularly useful when dealing with large tables, as it allows queries to be executed on smaller subsets, improving overall performance. Horizontal partitioning is often based on a specific criterion, such as a range of values, a hashing algorithm, or a location-based attribute.
Vertical Partitioning
Vertical partitioning involves dividing a dataset based on columns, where each partition holds a subset of columns. This technique is beneficial when certain columns are accessed more frequently than others, as it allows for efficient data retrieval by minimizing the amount of data read from disk. Vertical partitioning can be based on attributes related to data usage patterns, such as frequently accessed columns or columns with large data sizes.
Data Sharding
Data sharding takes partitioning a step further by distributing data across multiple servers, each responsible for a specific subset of data. Sharding allows for horizontal scalability, as the workload is distributed among multiple servers. However, sharding introduces additional complexity in terms of data distribution, query routing, and data consistency. Techniques such as consistent hashing and range-based sharding are commonly used to implement data sharding.
Backup and Restore Strategies
Implementing robust backup and restore strategies is essential for ensuring data integrity, providing point-in-time recovery options, and mitigating the risk of data loss. By regularly backing up data and establishing well-defined restore procedures, organizations can recover from various types of data-related issues, including hardware failures, logical errors, or accidental deletions.
Full Backups
A full backup involves creating a complete copy of the entire dataset. Full backups provide a baseline for restoration and ensure that all data is captured. While full backups offer comprehensive coverage, they can be time-consuming and resource-intensive, particularly for large datasets.
Incremental Backups
Incremental backups capture only the changes made to the dataset since the last backup, significantly reducing backup times and storage requirements. Incremental backups are performed more frequently than full backups and rely on previous full backups and subsequent incremental backups for restoration. However, the restore process may involve restoring multiple backups in chronological order.
Differential Backups
Differential backups capture the changes made since the last full backup, rather than the changes since the last backup. Differential backups offer a middle ground between full and incremental backups, providing faster restoration times than incremental backups while requiring less storage than full backups. However, the size of differential backups increases over time, as each differential backup includes all changes since the last full backup.
Data Restoration Best Practices
When it comes to data restoration, it is essential to follow best practices to ensure successful recovery and minimize downtime. These practices include regularly testing restore procedures, verifying backup integrity, maintaining offsite backups, documenting restore processes, and considering data encryption for backups to protect sensitive information. By adhering to these best practices, organizations can confidently restore data in the event of data loss or corruption.
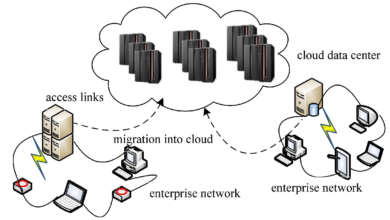
Cloud Integration and Hybrid Deployments
Cloud integration and hybrid deployments offer organizations flexibility, scalability, and cost-efficiency when it comes to data server configurations. By leveraging cloud services and combining on-premises infrastructure with cloud resources, organizations can optimize their data management and take advantage of the benefits offered by both environments.
Cloud Storage and Data Services
Cloud storage services provide scalable and durable storage options for data servers. By offloading data storage to the cloud, organizations can reduce on-premises storage costs, leverage built-in redundancy and data protection mechanisms, and easily scale storage capacity as needed. Additionally, cloud providers offer various data services, such as managed databases or data warehousing, which can simplify data management tasks.
Hybrid Infrastructure
Hybrid infrastructure combines on-premises infrastructure with cloud resources, allowing organizations to leverage the benefits of both environments. By adopting a hybrid approach, organizations can utilize on-premises servers for sensitive or highly regulated data, while leveraging the scalability and flexibility of the cloud for less critical workloads. Hybrid deployments enable organizations to optimize resource utilization, reduce costs, and seamlessly extend their data server configurations to the cloud.
Data Transfer and Integration
Transferring data between on-premises servers and the cloud requires robust connectivity and efficient data transfer mechanisms. Organizations can utilize dedicated network connections, such as Direct Connect or ExpressRoute, to establish high-speed connections between their data centers and cloud providers. Additionally, data integration tools and services can help synchronize data between on-premises and cloud environments, ensuring consistency and enabling real-time data processing across both infrastructures.
In conclusion, advanced data server configurations are essential for optimizing performance, ensuring high availability, and protecting your valuable data. By implementing the techniques discussed in this article, you can transform your data infrastructure into a robust and efficient system that meets the demands of modern businesses. Stay ahead of the curve and unlock the full potential of your data with these advanced configurations.